Improving Seeq Performance with Slow Datasources
Overview
Seeq is designed to query your process data, wherever it happens to live: in a historian like OSIsoft PI, or via OPC-HDA, or in a SQL database, or anywhere else. Generally, Seeq is not the system of record, and Seeq will query the datasource for data in an on-demand fashion. If you query a signal from your historian in Seeq for June to August 2018, Seeq will fetch only the data that it needs, and won't touch data outside of the requested time range, unless it is required by a calculation. This means that your Seeq data (analyses, topics, and calculations) can only be prepared as quickly as the source database can provide it. Some datasources can be slow and result in a slow experience for Seeq users.
Types of Datasource Slowness
Here are some possible reasons a datasource might be slow:
High latency: This means that any request, large or small, will have a relatively high time to process. High latency is usually caused by there being a large distance between the Seeq server and the datasource, either geographically, or in network topology. If your data is stored in one continent and Seeq is running in another, each query will have a natural delay. A request sent to the other side of the world will take about 150ms at least, due to the speed of light. You must also account for the configuration of the network – VPNs, proxies, and other layers that can increase the latency.
Low throughput: When throughput is low, small requests may return relatively quickly, but larger requests will be slow, usually proportional to the amount of data being handled. This could be due to hardware (CPU, memory), network limitations, inefficient database design, or contention between Seeq and other consumers of the same data. Seeq is rarely the only user of a datasource. It may be serving multiple use-cases: recording production data, generating daily reports, and longer-term data science research or ad-hoc exploration.
Solutions
Datasource Caching
Caching is a valuable strategy for improving the performance of both high latency or low throughput datasources. Seeq will always cache the results of calculations (formulas, value searches, and so on) so they do not need to be computed repeatedly, but it will not cache "raw" data (e.g. from the historian) by default. You can turn it on for raw data as well – on a signal-by-signal basis or for a datasource as a whole.
There are some important considerations for using caching:
When caching is turned on for a datasource and/or a particular signal, then data fetched from the datasource will be written to Seeq's data folder so that it can be quickly read from that location if it is ever requested again. This is the main benefit.
Caching performance is largely dictated by the speed of the storage device that houses Seeq's data folder. Execute seeq diag info at the Seeq Command Line Interface to view information on the performance of the storage device.
If the data in the source database is changing such that older sample values are back-filled or re-stated, then caching would prevent those updates from appearing in Seeq. (You can always clear a signal's cache from Seeq Workbench using Advanced section of the Item Properties pane.)
Since data is being written to Seeq's data folder, you must make sure to provide adequate storage space to accommodate the data that users are requesting.
Version R53.0.0 and later
You can configure the maximum size of the series cache folder with theCache/Persistent/Series/MaxSizeconfiguration option. Cache entries will be automatically pruned in a first-in-first-out basis when the cache folder exceeds the configured size, given in GiB. More information on setting configuration can be found here: Configuring Seeq.
Remote Agent
If your datasource has high latency due to its location, perhaps being in a different part of the world, then a remote agent may be a good option. Sometimes when Seeq queries a datasource, it requires multiple round-trip messages over the network, due to a limit in the amount of data that can be fetched at one time. A remote agent can improve performance by making these repeated requests from a nearby location, where the network latency is lower. Additionally, requests between Seeq and remote agents will be compressed, lowering the amount of bandwidth used. The result is a faster experience for users of Seeq. Details on setting up a remote agent are available at Installing and Upgrading a Seeq Remote Agent.
Connection Request Timeout
If queries to your datasource sometimes take a very long time (minutes, hours, or more), you may find it valuable to adjust the Connection Request Timeout parameter. By default, requests to a datasource like PI or OPC-HDA have a time limit of one hour before Seeq will give up and cancel the request.
To choose the appropriate Connection Request Timeout, you want to choose a value large enough that any "reasonable" query can complete in that amount of time, but not much larger. If your queries all run within a minute or two, you might set the Connection Request Timeout to 5 or 10 minutes. Having a lower Connection Request Timeout ensures that very large requests won't fill up the request queue in Seeq for too long.
You can raise or lower the timeout by setting a property on the datasource item in Seeq's database. See below for instructions.
Open the API Reference tool Click the top-right menu in Seeq and select “Help Center.” Then choose “API Reference,” which will open the Seeq API Reference page in a new tab. |   |
Find the ID of the datasource Choose Datasources, then GET /datasources, then click "Try it out". In the "Response Body" block, find the desired datasource by name, and copy the "id" field. Alternatively, you can use the Seeq Command Line Interface for this step, but we'll need to use the Seeq API Reference for the next step. | 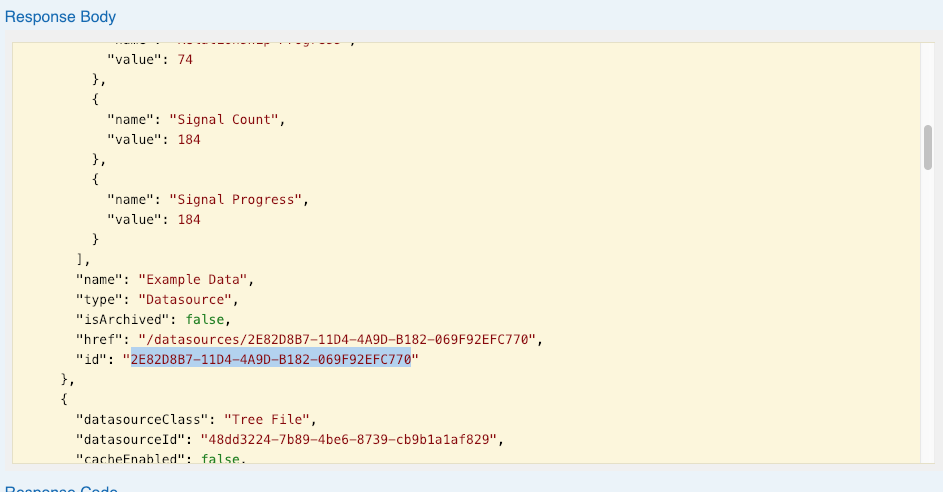 |
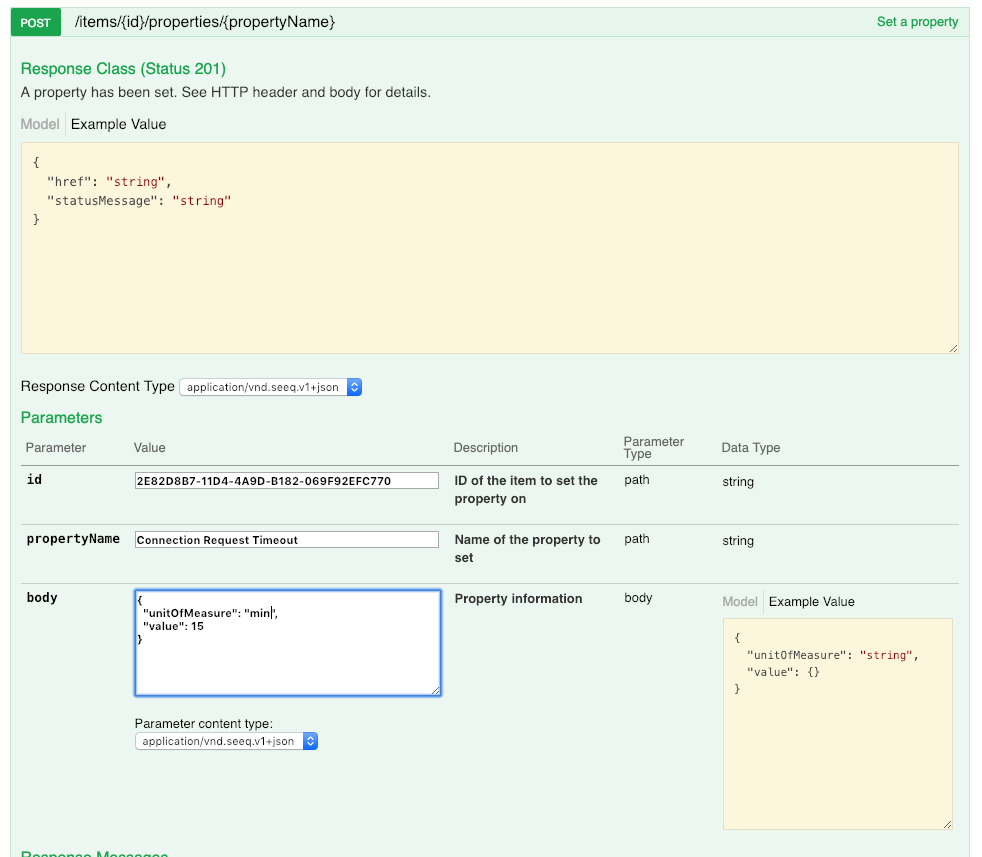
Set the timeout property Then, switch to the Items section, POST /items/{id}/properties/{propertyName}. Examples of valid timeouts are:
CODE
CODE
|  |
Last, restart Seeq server. Changes to "Connection Request Timeout" will only take effect when the server starts up. |
Connection Request Limits
Most connectors have two options for configuring limits on how requests are processed at a per-connection level.
Description | |
|---|---|
MaxConcurrentRequests | Defaults to unlimited ( |
MaxResultsPerRequest | Defaults to unlimited ( |
You may need to lower both of these values across all your connections if the machine hosting the Agent is straining for memory and/or CPU. In other words, it is better to restrict the amount of data being handled concurrently than to overload the Agent with concurrent requests that cause excessive CPU and memory usage (particularly if memory must be paged to disk to accommodate the requests).