Creating a Query Definition for the SQL Connector
Overview
The SQL Connector accesses data in SQL tables as signals, conditions, and scalars. By adding query definitions to the SQL connector configuration, thousands of signals, conditions, and scalars can be created at once. In this article, the format of the query definition is explained through a series of examples.
After a connection is established with the SQL database and a query definition is provided, all the signals, conditions, and scalars found are indexed by Seeq. The SQL queries that define the signal, condition or scalar are run against the database during indexing. Later when a signal or condition is trended in Seeq, queries are also run against the database to access the signal samples or condition capsules.
Getting Started
You don't need to read this entire article to get started. Instead, read through the 1st example, try something simple, and then proceed on to the other examples as you increase the sophistication of your SQL integration.
The Query Definition JSON Model
QueryDefinition Configuration
More information on configuring these values can be found in Creating a Query Definition for the SQL Connector
Property Name | Default Value | Data Type | Description |
|---|---|---|---|
| String | The name of the query definition. This value will be used as part of the Data ID. Changing this value after analyses have been created will break those worksheets/topics. | |
| Enum
| Defines whether this query will result in a set of Signals, Conditions, or Scalars. | |
| String | The base SQL query that will be used for this query. | |
| Boolean | If true, the query is used to discover new data items. If false, no data will be indexed from this query. | |
EpochTimeUnit | null |
| The units of time used in epoch format time columns for this query. Leave this set to “null” for all other time formats. |
| Boolean | If true, every discovered value will attempt to be queried for to determine if the query is valid. This should be set to false once the query has been identified to be working. | |
| Array[Variable] | Allows for dynamic value replacements in a Query Configuration. See using variables in the SQL connector configuration. | |
| Array[Property] | Specifies the properties that will be indexed as metadata for the data item. | |
| Array[CapsuleProperty] | Only valid when The properties that should be associated with each capsule. | |
| true | Boolean | When set to `true`, the queries used to retrieve samples/capsules will be tested when the signals/conditions are indexed. Any problems encountered are logged. This allows query problems to be discovered prior to trending the signal/condition. This should be set to false once the configuration is successful. |
| false | Boolean | Whether Capsules with a |
| 0 | Integer | The duration into the future, following the current time, within which the system searches for the latest capsule that has a non-null end time. |
Property Configuration
Property Name | Default Value | Data Type | Description |
|---|---|---|---|
| String | The name of the property. | |
| String | The value of the property. | |
| String | The unit of measure for the property value, or |
CapsuleProperty Configuration
Property Name | Default Value | Data Type | Description |
|---|---|---|---|
| String | The name of the capsule property. | |
| String | The value of the capsule property. | |
| String | Optional: The column from the result set that the value should be taken. | |
| String | The unit of measure for the capsule property value, or |
Variable Configuration
Property Name | Default Value | Data Type | Description |
|---|---|---|---|
| Array[String] | A list of names that represent the individual variable names. | |
| Array[Array[String]] | A list of values that are associated with the names. There must be an equal number of values as there are names. Position is important between the | |
| String | Optional: The query that will produce the values for the variable names. |
Connector Rules
If you are reading this for the first time, the rules will be explained through the examples. They are presented first due to their importance and for future ease of reference.
General
The first column must be either a supported date/time column type or a whole number numeric type representing an epoch time value. Those column types that include time zone information are marked below with an * below. If using a date/time column type that doesn't include zone information, remember to set the TimeZone field in the configuration file appropriately. For epoch format time, the UTC time zone is assumed and the TimeZone field is ignored.
MySql: year, date, datetime, timestamp*
MS SQL Server: date, smalldatetime, datetime, datetime2, datetimeoffset*
Oracle: date, timestamp, timestamp with time zone*, timestamp with local time zone*
Postgres: date, timestamp, timestamp with time zone*
Amazon Redshift: date, timestamp, timestamp with time zone*
Vertica: date, smalldatetime, datetime, timestamp, timestamp with time zone*
SAP HANA: date, timestamp, seconddate
Athena: date, timestamp*
Snowflake: date, datetime, timestamp, timestamp_ntz, timestamp_ltz*, timestamp_tz*
Databricks: timestamp*
Signals
The first column must be the key (x-axis) and the second column must be the value (y-axis). The error
SQ-1400will be generated if the query doesn’t have enough columns for a Signal.Seeq does not support multiple samples with the same key.
Details: This means Seeq does not support multiple rows with the same value in the key column (the first column). If your query returns multiple samples with the same key, only the last sample received will be used. Even when using "ORDER BY key" in SQL queries, SQL databases do not always return the rows in the same order when there are multiple rows with the same value in the key column. This means that the sample used by Seeq may change every time the data is accessed.
These properties must be defined: Name, Interpolation Method, Maximum Interpolation.
If the signal is a string signal, the property Value Unit Of Measure must also be defined and set to "string".
Conditions
The first column must be the capsule start time and the second column must be the capsule end time. The error
SQ-1400will be generated if the query doesn’t have enough columns for a Condition.These properties must be defined: Name, Maximum Duration.
Scalars
When generating Seeq Scalars from a query that returns exactly one value (Example):
The first column must be the constant. Only the first row of the query result will be used so the value of interest must also be in the first row.
These properties must be defined: Name
If the scalar is a string and a UOM was specified, the UOM will be ignored.
When generating Seeq Scalars from a query that returns many scalar values (Example):
The first column must be a static constant that uniquely identifies a Scalar value. This could be an ID Number, a name, a composite of multiple values etc.
The second column must be the Scalars value.
Any number of additional columns can be selected for as well in any order. The values of these columns can be referenced in the Scalar’s properties.
These properties must be defined: Name
If the scalar is a string and a UOM was specified, the UOM will be ignored.
Once signals, conditions and scalars have been created using a query definition, don't change the query definition name or the variable names. These both contribute to a unique identifier for the signal/condition. If you change them, the original signal/condition (with the original identifier) will be archived and a new signal/condition (with a new identifier) will be created. If you had calculations, worksheets, etc referring to the signals/conditions with the original identifiers, those will not be automatically updated to point to the new signals/conditions with the new identifiers.
Adding Signals, Conditions and Scalars
After a connection is established, signals, conditions and scalars can be added by adding Query Definitions.
Below is an excerpt of the SQL Connector configuration file showing where the Query Definitions should go. In this example, signals and conditions are being defined for the Oracle connection. Note that the Query Definitions are located inside the braces associated with the Oracle connection.
Configuration File Excerpt
{
"Version" : "com.seeq.link.connectors.sql2.config.SqlConnectorV2ConfigV1",
"Connections" : [ {
"Name" : "My Oracle Database",
"Id" : "cd3c8788-7fb9-4637-b843-8f1e2c08be55",
"Enabled" : true,
"Type" : "ORACLE",
...
"MaxConcurrentRequests" : 10000,
"MaxResultsPerRequest" : null,
"QueryDefinitions" : [ {
} ]
}, {
"Name" : "My Postgres Database",
"Id" : "cd3c8788-7fb9-4637-b843-8f1e2c081234",
"Enabled" : true,The details of the Query Definition content are explained in the following examples.
JSON Tips
The JSON query definitions are some of Seeq's more complex JSON files. Getting all the JSON formatting just right can be tricky. Here are some tips:
JSON doesn't support comments
Each field's value must be on a single line without line breaks
Check your "
[ { ," formatting with a json validator such as https://jsonlint.com/Indenting doesn't matter but if done, it is easier to spot problems. There are tools that will apply indenting for you such as https://jsonformatter.curiousconcept.com/ or http://jsonprettyprint.com/.
If using Notepad++ to edit json files, the addin "jstool" does formatting and has a "json viewer": the Jslint add-in is a Javascript validator, but if you set the file language type to JavaScript it will validate json (json is, for practical purposes, mainly a JavaScript subset)
Performance Tips
Retrieving partitioned data
When using SQL Connector to connect to warehouse or lakehouse systems, the data is often partitioned. In addition to partitioning by facility or tag structure, which can be achieved through the use of variables (as shown above), time series data is often partitioned by timestamp components as well. The SQL Connector is able to pull out parts of the start and end timestamp into the partitions required to isolate the query to just the partitions of interest. This can be done by inserting ${start:...} and ${end:...} keywords into the "Sql" property of a Query Definition of type SIGNAL and CONDITION.
Configuration File Excerpt
"QueryDefinitions" : [ {
"Name" : "MyVolumeSignal",
"Type" : "SIGNAL",
"Sql": "SELECT Time, Value FROM dbo.SensorDataPartionedView WHERE Year >= ${start:yyyy} AND Year <= ${end:yyyy} AND Month >= ${start:month} AND Month <= ${end:month} AND Day >= ${start:day} AND Day <= ${end:day}",When using ${start:<pattern>} and ${end:<pattern>} keywords, the pattern may be any valid sequence of symbols according to https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html, for example {start:yyyy-MM-dd HH:mm:ss.SSSSSS}.
Additionally from the pattern format mentioned above, Seeq offers the following additional patterns:
${start:month}= the month from the start of the request (will be set to 01 when the query crosses years)${start:day}= the day from the start of the request (to be set to 01 when the query crosses months)${end:month}= the month from the end of the request (will be set to 12 when the query crosses years)${end:day}= the day from the end of the request (to be set to 31 when the query crosses months)
The additional patterns mentioned above are specific to Seeq and are not standard Java DateTimeFormatter patterns.
To explain why the additional patterns above are needed, let’s consider a trivial example with one table, representing a signal named “volume”.
Table: volume
=============
timestamp, value y m d
'2016-08-16 10:00:00', 2.1 2016 8 16
'2016-08-17 10:00:00', 5.3 2016 8 17
'2016-09-16 10:00:00', 2.7 2016 9 16
'2017-01-03 10:00:00', 2.0 2017 1 3The Sql for unpartitioned access would be: select timestamp, value from volume.
An Sql that will use partitioning by year, month and day may be imagined like select timestamp, value from volume WHERE y>=${start:yyyy} and y<=${end:yyyy} and m>=${start:MM} and m<=${end:MM} and d>=${start:dd} and d<=${end:dd}.
The problem is that if a user makes a query to get all the values between 2016-08-17 00:00:00 and 2016-09-16 23:59:00 , the system will do a query y>=2016 and y<=2016 and m>=8 and m<=9 and d>=17 and d<=16. There is no matching records for d>=17 and d<=16. Because the month boundary has crossed, the day filter should be replaced to be a “pass all filter” (i.e. d>=1 and d<=31). This cannot be obtained by using ${start:dd} and ${end:dd} patterns, therefore we needed to create ${start:day} and ${end:day} (and similarly ${start:month} and ${end:month}) to account for year and month crossings.
Example SQL Tables
The following examples will use these SQL tables. Most of the examples are illustrated using a Postgres datasource but the concepts are the same for all database types. Syntax may vary slightly for other database types.
Simple Query Definitions
Simple Signal (Example 1 - Volume Signal)
SQL signals have sample data that comes from a query such as this:
SELECT myKey, myValue1 FROM myTable
Note that the signal's key (x-axis) is the first column and the signal's value (y-axis) is the second column. This follows the connector rules.
Using the example table LabSignals, we could create a volume signal with the query:
SELECT run_start, volume FROM LabSignals
To create this signal, add a Query Definition to the configuration file. The minimum query definition looks like:
Query Definition for a simple signal
"QueryDefinitions" : [ {
"Name" : "MyVolumeSignal",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, volume FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "Volume",
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "2day",
"Uom" : "string"
} ]
} ]The first name field,
"Name" : "MyVolumeSignal", is the name of the Query Definition and isn't displayed prominently so it doesn't have to be a pretty name.Every signal needs a minimum of 3 properties.
The signal name which is the name you'll see in the UI.
The interpolation method.
The maximum interpolation.
Simple String Signal (Example 2 - ID Signal)
The minimum query definition for a string signal is nearly identical to the previous example except that the Value Unit of Measure property must also be defined and set to "string".
Using the example table LabSignals, we could create an ID signal with the query.
SELECT run_start, id FROM LabSignals
The minimum query definition looks like the following. I chose to make this a step interpolated signal.
Query Definition for a simple signal
"QueryDefinitions" : [ {
"Name" : "MyIdSignal",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, id FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "ID",
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "step",
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "2day",
"Uom" : "string"
}, {
"Name" : "Value Unit Of Measure",
"Value" : "string",
"Uom" : "string"
} ]
} ]Simple Condition (Example 3 - Run Capsules)
SQL conditions have capsule data that comes from a query such as
SELECT myStart, myEnd FROM myTable
Note that the start is the first column and the end is the second column. This follows the connector rules.
Using the example table LabSignals, we could create a condition with a capsule for each run using the query
SELECT run_start, run_end FROM LabSignals
To create this condition, add a Query Definition to the configuration file. The minimum query definition looks like:
Query Definition for a simple condition
"QueryDefinitions" : [ {
"Name" : "MyRunsCondition",
"Type" : "CONDITION",
"Sql" : "SELECT run_start, run_end FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "Runs",
"Uom" : "string"
}, {
"Name" : "Maximum Duration",
"Value" : "3h",
"Uom" : "string"
} ]
} ]The first name field, "Name" : "MyRunsCondition", is the name of the Query Definition and isn't displayed prominently so it doesn't have to be a pretty name.
Every condition needs a minimum of 2 properties.
The condition name.
The Value property on line 9 above, is the name you'll see in the UI.
The maximum duration.
Simple Scalars
Two styles of Query Definition can be used to generate scalars in Seeq. Which you use should be determined based on the number of scalars that need to be generated and the ease with which they can be retrieved with their values in a single result set.
Single Scalar Query Definitions should be used when you have a small number of scalar values to index, or when there is no reasonable way to query the database to retrieve a collections of uniquely identified scalars with their value in a single set of results. This style is assumed when the Sql property of the Query Definition has a select statement with exactly 1 field specified.
Multiple Scalar Query Definitions should generally be the preferred style. It should be used whenever multiple scalars can be retrieved with their value in a single query. This style is assumed when the Sql property of the Query Definition has a select statement with 2 or more fields specified. Results similar to those achieved with Multiple Scalar Query Definitions can be achieved by using the Single Scalar style with a Variable property; however, Multiple Scalar Query Definitions are more efficient and can index scalars in significantly less time.
Single Scalar (Example 4a)
Single Scalars have a constant value that comes from a query such as
SELECT myConstant FROM myTable
Note that the constant value is found in the first column and first row of the result. This follows the connector rules. Only one column can be included in the result set as including more will cause the query to be handled as a Multiple Scalar query.
Using the example table LabSignals, we could create a scalar using the query
SELECT volume FROM LabSignals WHERE id='WO000113'
To create this scalar, add a Query Definition to the configuration file. The minimum query definition looks like:
Query Definition for a simple Single Scalar
"QueryDefinitions" : [ {
"Name" : "MyConstantDefinition",
"Type" : "SCALAR",
"Sql" : "SELECT volume FROM LabSignals WHERE id='WO000113'",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "MyConstant",
"Uom" : "string"
}, {
"Name" : "Unit Of Measure",
"Value" : "litre",
"Uom" : "string"
} ]
} ]The first name field, "Name" : "MyConstantDefinition", is the name of the Query Definition and isn't displayed prominently so it doesn't have to be a pretty name.
Every scalar needs a minimum of 1 property.
The scalar name which is the name you'll see in the UI.
Unit of Measure (or Value Unit of Measure) is an optional property. If the scalar came from a string SQL column type or from a date/time SQL column type, the uom will be ignored.
Scalar Timestamps
SQL scalars coming from a date/time column type will be converted to Seeq timestamps which are Unix epoch timestamps with units nanoseconds. This makes them easy to use in calculations.
Multiple Scalars (Example 4b)
Multiple Scalar queries derive many constant values from a single SQL query where each row in the result defines a scalar.
SELECT id, value, name, description FROM myConstants
The result must have at least 2 columns where the first is a unique identifier for the scalar and the second is the value. Any number of additional columns are permitted and their values can be referenced in Properties of the scalar being defined.
Using the LabScalarConstants table as an example, we could create a single QueryDefinition that generates a Seeq scalar for each row while also extracting relevant information with no additional queries:
Query Definition for a simple Multiple Scalar
"QueryDefinitions" : [ {
"Name" : "MyMultipleLabConstants",
"Type" : "SCALAR",
"Sql" : "SELECT id, value, name, description, units FROM LabScalarConstants",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "${name}",
"Uom" : "string"
}, {
"Name" : "Description",
"Value" : "Descr: ${description}",
"Uom" : "string"
}, {
"Name" : "Unit Of Measure",
"Value" : "${units}",
"Uom" : "string"
} ]
} ]A combination of the QueryDefinition’s Name and the scalar’s first column value are is used to identify each scalar in Seeq. Care should be taken to select static values for these as changing them will cause existing Seeq scalars to be archived.
The first select field must specify a unique identifier for each scalar and the second must specify the scalar’s value. Any number of additional columns are allowed and their order is not significant.
While the
Sqlvalue must be aSELECTstatement, it does not need to simply select the entire contents of a single table. Ranges and joins of arbitrary complexity can be used to create the desired selection of constant values.The result of every select field specified in the query can be referenced in the scalar’s list of
Properties.Separate ID and Name select fields are not necessary if a single value can serve both purposes for each constant.
As with Single Scalar queries, the Name Property is required. Unit of Measure and Description are optional, but recommended, properties.
Additional Properties (Example 5)
There can be additional properties beyond the required properties. Common Seeq properties are:
Description (signals and conditions)
Value Unit Of Measure (signals only)
You can also make up your own properties such as the "SomeOtherProperty" shown below. In this case, I want the value to be treated as a number rather than a string and so the Value field has no quotes around it.
Here is the signal query definition with a few more properties defined:
Query definition for a simple signal with more properties
"QueryDefinitions" : [ {
"Name" : "MyVolumeSignal",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, volume FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "Volume",
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "2day",
"Uom" : "string"
}, {
"Name" : "Description",
"Value" : "The volume of product produced during a run",
"Uom" : "string"
}, {
"Name" : "Value Unit Of Measure",
"Value" : "litre",
"Uom" : "string"
}, {
"Name" : "SomeOtherProperty",
"Value" : 12345.6789,
"Uom" : "kg"
} ]
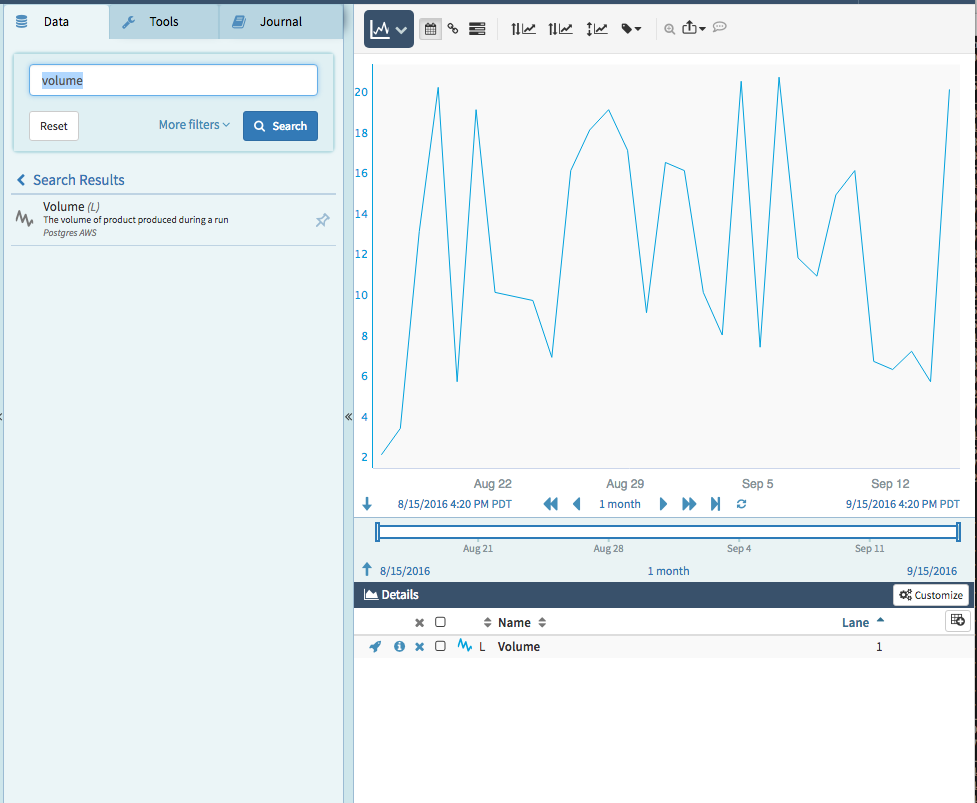
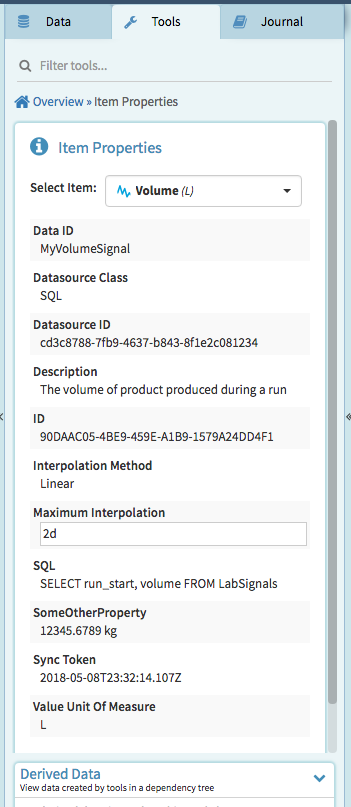
} ]This is how this signal will look in Seeq along with the information as shown in the Item Properties panel. Note that there is an "SQL" property created automatically. This is useful if for checking what SQL query is behind a Seeq signal or condition. In this example, there is just one signal. When you have thousands of SQL signals, this will come in handy.
Connector Rule: The First Column Must Have a Name
One of the SQL Connector's rules is that the first column (signal key or condition start) must have a name. This rule was followed in all the previous examples. The first column is named "run_start".
The reason that a name is required is that Seeq looks at the time range that you are interested in and only requests the portion of the SQL table that is relevant to that time range. If the SQL table is very large, this is much faster than requesting the data from the entire table. Therefore, the query
SELECT run_start, volume FROM LabSignals
is modified by Seeq to be of the form
SELECT run_start, volume FROM LabSignals WHERE run_start > timestamp '2016-08-14 22:32:02.727096955' AND run_start < timestamp '2016-09-15 02:45:40.908914815'
The name of the first column is needed for the WHERE clause.
Here is an example of a Postgres query that doesn't follow this rule:
SELECT run_start + INTERVAL '6 hours', volume FROM LabSignals
But it can be modified to follow the rules by:
naming the first column
wrapping the query in an extra SELECT statement and naming the table
SELECT * FROM (SELECT run_start + INTERVAL '6 hours' AS myKey, volume FROM LabSignals) AS foo
At which point Seeq has enough information to add the WHERE clauses:
SELECT * FROM (SELECT run_start + INTERVAL '6 hours' AS myKey, volume FROM LabSignals) AS foo WHERE myKey > timestamp '2016-08-14 23:14:04.64716377' AND myKey < timestamp '2016-09-15 01:29:39.499100425' ORDER BY myKey
Scenarios that need this sort of modification include:
first column is not a column directly but the result of manipulating that column. Examples: CAST, time shift, etc.
the column name is ambiguous due to using a JOIN and/or schemas
SELECT *
In general, using SELECT * is not recommended. The query
SELECT * FROM LabSignals
could successfully produce a signal but it pulled 5 additional columns that were not needed. Transferring extra columns of data takes time which means that it will take longer to load data.
Condition with Capsule Properties (Example 6 - Run Capsules with Additional Properties)
Instead of making signals out of each measurement, let's instead record the measurements as properties of each capsule. To do this, I need to add volume and thickness to my main SQL query. Then in each of the capsule properties, I can reference those additional columns by using the keyword ${columnResult} in the Value field and specifying the column name in the Column field. I also added an additional capsule property that is just set to "red".
Query Definition with Capsule Properties
"QueryDefinitions" : [ {
"Name" : "MyRunsCondition",
"Type" : "CONDITION",
"Sql" : "SELECT run_start, run_end, volume, thickness FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "Runs",
"Uom" : "string"
}, {
"Name" : "Maximum Duration",
"Value" : "3h",
"Uom" : "string"
} ],
"CapsuleProperties" : [ {
"Name" : "volume",
"Value" : "${columnResult}",
"Column" : "volume",
"Uom" : "string"
}, {
"Name" : "thickness",
"Value" : "${columnResult}",
"Column" : "thickness",
"Uom" : "string"
}, {
"Name" : "some other property",
"Value" : "red",
"Uom" : "string"
} ]
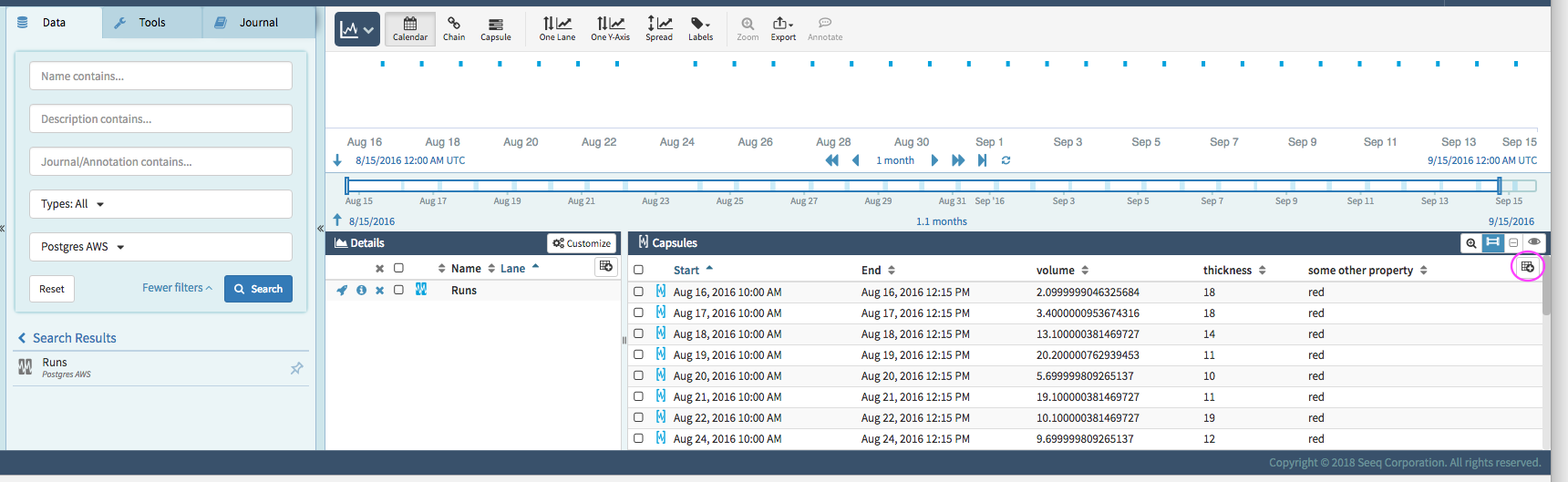
} ]This query definition looks like this in Seeq. The properties of each capsule can be observed in the Capsule Details pane. By default, only the start is shown but the others can be added using the circled button. The capsules can be sorted by any of the properties. A new condition containing only a subset of the capsules can be created by filtering on the properties. For more information, see the keep() and property() documentation in the formula tool.
Assigning Persistent IDs to Capsules (Example 6A)
In many use cases, it's beneficial for capsules to maintain a consistent identity across data refreshes or small changes—especially when capsules are used in visual selections, annotations, notifications, or UI interactions. Seeq now supports assigning a persistent capsule ID by designating a capsule property to serve as its unique identifier.
Why Use Persistent Capsule IDs?
By default, any change to a capsule—such as its start time, end time, or properties—will cause it to be treated as a distinct capsule, even if it represents the same logical event, such as an alarm or batch. This behavior can disrupt user workflows that rely on stable capsule references.
To solve this, Seeq allows a condition to specify which capsule property acts as a capsule ID.
This feature is particularly useful when working with external event sources such as alarm databases, where each event already has a well-defined identifier.
How to Assign a Capsule ID Property
To assign a persistent capsule ID, define a capsule property in your SQL connector query definition with a specific name: "Capsule ID Property". The value of this property should exactly match the name of an existing capsule property that contains the actual ID (e.g., alarm_id, batch_id, etc.).
Here is an example of how to define this in your query definition:
"QueryDefinitions" : [ {
"Name" : "MyRunsCondition",
"Type" : "CONDITION",
"Sql" : "SELECT run_start, run_end, volume, thickness, alarm_id FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Properties" : [ {
"Name" : "Name",
"Value" : "Runs",
"Uom" : "string"
}, {
"Name" : "Maximum Duration",
"Value" : "3h",
"Uom" : "string"
}, {
"Name" : "Capsule ID Property",
"Value" : "Alarm ID",
"Uom" : "string"
} ],
"CapsuleProperties" : [ {
"Name" : "volume",
"Value" : "${columnResult}",
"Column" : "volume",
"Uom" : "string"
}, {
"Name" : "thickness",
"Value" : "${columnResult}",
"Column" : "thickness",
"Uom" : "string"
}, {
"Name" : "some other property",
"Value" : "red",
"Uom" : "string"
}, {
"Name" : "Alarm ID",
"Value" : "${columnResult}",
"Column" : "alarm_id",
"Uom" : "string"
} ]
} ]This tells Seeq to use the value of the alarm_id property as the unique ID for each capsule. Capsules with the same alarm_id value should be avoided, as Seeq will treat them as the same capsule for purposes such as:
Annotations attached to the capsule
Selection and highlighting in the UI
Notifications triggered by the capsule
Persistence of capsule references across data reloads
Note: The property referenced by "Value" (e.g., alarm_id) must also be defined as a capsule property in the query definition and must have a stable, unique value for each logical capsule.
Using Variables
A Signal per Measurement (Example 7)
The simple signal query definition above creates just one signal. But that table has four signals of similar form.
SELECT run_start, volume FROM LabSignals
SELECT run_start, temperature FROM LabSignals
SELECT run_start, thickness FROM LabSignals
SELECT run_start, cost FROM LabSignals
All N signals can be created with one query definition by using a variable such as ${myMeasurement}.
SELECT run_start, ${myMeasurement} FROM LabSignals
where ${myMeasurement} = volume, temperature, thickness, cost
Signal Query Definition Using a Variable
"QueryDefinitions" : [ {
"Name" : "MyMeasurementSignals",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, ${myMeasurement} FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Variables" : [ {
"Names" : [ "myMeasurement" ],
"Values" : [ [ "volume" ], [ "temperature" ], ["thickness"], ["cost"] ]
} ],
"Properties" : [ {
"Name" : "Name",
"Value" : "Measurement of ${myMeasurement}",
"Uom" : "string"
}, {
"Name" : "Description",
"Value" : "This is a measurement of the ${myMeasurement} of our product",
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "2d",
"Uom" : "string"
} ]
} ]
Note the addition of a variable to the query definition. In this case, it has been hardcoded to have 4 values which means that this query definition will create 4 signals. The first signal is created from the above query definition but with every instance of ${myMeasurements} replaced by volume. The 2nd signal is created using temperature. And so on.
Signal Name | Description | Samples come from: | |
1 | Measurement of volume | This is a measurement of the volume of our product | SELECT run_start, volume FROM LabSignals |
2 | Measurement of temperature | This is a measurement of the temperature of our product | SELECT run_start, temperature FROM LabSignals |
3 | Measurement of thickness | This is a measurement of the thickness of our product | SELECT run_start, thickness FROM LabSignals |
4 | Measurement of cost | This is a measurement of the cost of our product | SELECT run_start, cost FROM LabSignals |
Many Signals per Measurement (Example 8)
If there were 200 signals of this form, hardcoding the values for ${myMeasurement} would be tedious. Instead, the variable values can be defined by another SQL query.
Query Definition Using a Variable Defined by SQL
"QueryDefinitions" : [ {
"Name" : "MyMeasurementSignals",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, ${myMeasurement} FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Variables" : [ {
"Names" : [ "myMeasurement" ],
"Values" : [ [ "${result}" ] ],
"Sql" : "select column_name from information_schema.columns where table_name='labsignals' and column_name!='run_start' and column_name!='run_end' and column_name!='id'"
} ],
"Properties" : [ {
"Name" : "Name",
"Value" : "Measurement of ${myMeasurement}",
"Uom" : "string"
}, {
"Name" : "Description",
"Value" : "This is a measurement of the ${myMeasurement} of our product",
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "2d",
"Uom" : "string"
} ]
} ]Using ${result} for the Values field indicates that the values are to come from the SQL query response defined on the next line.
This query returns every column name in the table excluding run_start and run_end. This syntax is Postgres syntax. The syntax for your database may be different.
The results of this query definition look like this in Seeq.
Extracting Description and UOM from Other Tables (Example 9)
Along with the example SQL table LabSignals, there is another table LabSignalMetadata that contains description and unit of measure information. Here is a more advanced query definition that uses additional SQL queries to utilize that description and unit of measure information for each signal.
Query Definition using information from multiple tables
"QueryDefinitions" : [ {
"Name" : "MyMeasurementSignals",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, ${myMeasurement} FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Variables" : [ {
"Names" : [ "myMeasurement" ],
"Values" : [ [ "${result}" ] ],
"Sql" : "select column_name from information_schema.columns where table_name='labsignals' and column_name!='run_start' and column_name!='run_end' and column_name!='id'"
} ],
"Properties" : [ {
"Name" : "Name",
"Value" : "Lab ${myMeasurement}",
"Uom" : "string"
}, {
"Name" : "Description",
"Value" : "${result}",
"Sql" : "SELECT description FROM LabSignalMetadata WHERE measurement='${myMeasurement}'",
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "2d",
"Uom" : "string"
}, {
"Name" : "Value Unit Of Measure",
"Value" : "${result}",
"Sql" : "SELECT units FROM LabSignalMetadata WHERE measurement='${myMeasurement}'",
"Uom" : "string"
} ]
} ]The results of this query definition look like this in Seeq. Notice that each signal now has a meaningful description and unit of measure that were pulled from the LabSignalMetadata table.
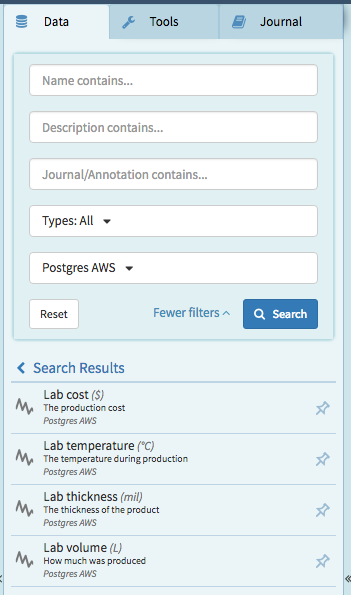
Query Definition with Multiple Variables (Signal per Run,Measurement)
This example will use the SQL table fom (figure of merit).
fom Table (Postgres format)
CREATE TABLE fom
(
fom_time timestamp null,
fom_value double precision null,
run integer null,
fom_type varchar(50) null
);
INSERT INTO fom (fom_time, fom_value, run, fom_type) VALUES
('2016-08-16 10:00:00', 2.1, 2, 'thickness' ),
('2016-08-17 10:00:00', 3.4, 1, 'volume' ),
('2016-08-18 10:00:00',13.1, 1, 'temperature'),
('2016-08-21 10:00:00',19.1, 4, 'thickness' ),
('2016-08-22 10:00:00',10.1, 1, 'volume' ),
('2016-08-22 10:00:00',14.1, 1, 'temperature'),
('2016-08-24 10:00:00', 9.7, 5, 'thickness' ),
('2016-08-19 10:00:00',20.2, 2, 'volume' ),
('2016-08-20 10:00:00', 5.7, 2, 'temperature'),
('2016-08-25 10:00:00', 6.9, 1, 'thickness' ),
('2016-08-26 10:00:00',16.1, 1, 'volume' ),
('2016-08-27 10:00:00',18.1, 1, 'temperature'),
('2016-08-30 10:00:00', 9.1, 4, 'thickness' ),
('2016-08-31 10:00:00',16.5, 5, 'volume' ),
('2016-09-01 10:00:00',16.1, 4, 'temperature'),
('2016-08-28 10:00:00',19.1, 5, 'thickness' ),
('2016-08-29 10:00:00',17.1, 5, 'volume' ),
('2016-09-02 10:00:00',10.1, 4, 'temperature'),
('2016-09-03 10:00:00', 8.0, 4, 'thickness' ),
('2016-09-04 10:00:00',20.5, 1, 'volume' ),
('2016-09-05 10:00:00', 7.4, 2, 'temperature'),
('2016-09-06 10:00:00',20.7, 4, 'thickness' ),
('2016-09-07 10:00:00',11.8, 1, 'volume' ),
('2016-09-08 10:00:00',10.9, 4, 'temperature'),
('2016-09-09 10:00:00',14.9, 5, 'thickness' ),
('2016-09-10 10:00:00',16.1, 2, 'volume' ),
('2016-09-11 10:00:00', 6.7, 4, 'temperature'),
('2016-09-12 10:00:00', 6.3, 4, 'thickness' ),
('2016-09-13 10:00:00', 7.2, 2, 'volume' ),
('2016-09-14 10:00:00', 5.7, 1, 'temperature'),
('2016-09-15 10:00:00',20.1, 3, 'thickness' );This table has signals for thickness, volume, and temperature over runs 1-5. The queries are of the form:
SELECT fom_time, fom_value FROM fom WHERE run=1 AND fom_type='thickness'
SELECT fom_time, fom_value FROM fom WHERE run=1 AND fom_type='volume'
SELECT fom_time, fom_value FROM fom WHERE run=2 AND fom_type='thickness'
etc.
All of these signals can be created using one query definition that has two variables.
SELECT fom_time, fom_value FROM fom WHERE run=${run} AND fom_type='${fom}'
where ${run} = 1,2,3,4,5 and ${fom} = thickness, volume, temperature.
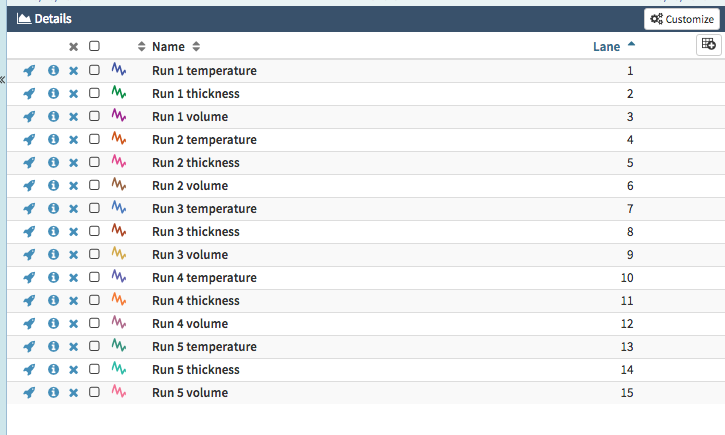
Signal for every possible combination of run and fom_type (Example 10)
${run} has 5 values and ${fom} has 3 values. The following query definition will produce a signal for every possible combination of ${run} and ${fom} which is 5 x 3 = 15 signals.
Query Definition using Every Possible Combination of Multiple Variables
"QueryDefinitions" : [ {
"Name" : "MyFomUseCase",
"Type" : "SIGNAL",
"Sql" : "SELECT fom_time, fom_value FROM fom WHERE run = ${myRun} AND fom_type='${myType}'",
"Enabled" : true,
"TestMode" : false,
"Variables" : [ {
"Names" : [ "myRun" ],
"Values" : [ [ "${result}" ] ],
"Sql" : "select distinct run from fom"
}, {
"Names" : [ "myType" ],
"Values" : [ [ "${result}" ] ],
"Sql" : "select distinct fom_type from fom"
} ],
"Properties" : [ {
"Name" : "Name",
"Value" : "Run ${myRun} ${myType}",
"Sql" : null,
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Sql" : null,
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "24d",
"Sql" : null,
"Uom" : "string"
} ]
} ]
Signal for every existing combination of run and fom_type (Example 11)
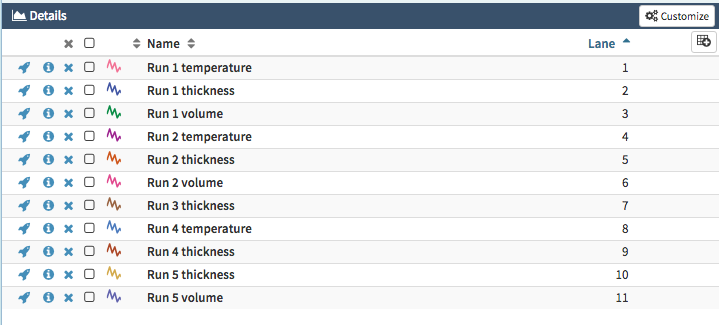
If you examine the SQL table fom, you'll notice that not every run measures every figure of merit. For example, there is no temperature measurement for run 5. The previous example produces a signal called Run 5 Temperature but it will have no samples. This may or may not be desirable depending on the use case. If this is not desirable, one can instead write a query definition that creates a signal for every existing combination of run and fom_type rather than every possible combination. Note that the previous example had two variable definitions. This example has combined them into one.
Query Definition using Every Existing Combination of Multiple Variables
"QueryDefinitions" : [ {
"Name" : "MyFomUseCase",
"Type" : "SIGNAL",
"Sql" : "SELECT fom_time, fom_value FROM fom WHERE run = ${myRun} AND fom_type='${myType}'",
"Enabled" : true,
"TestMode" : false,
"Variables" : [ {
"Names" : [ "myRun", "myType" ],
"Values" : [ [ "${result}" ] ],
"Sql" : "select distinct run, fom_type from fom"
} ],
"Properties" : [ {
"Name" : "Name",
"Value" : "Run ${myRun} ${myType}",
"Sql" : null,
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Sql" : null,
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "24d",
"Sql" : null,
"Uom" : "string"
} ]
} ]This query definition only produces 11 signals:
Many Variables
There is no limit to the number of variables that can be used. If a query definition had 5 variable definitions:
variable definition 1: 5 values
variable definition 2: 2 values
variable definition 3: 10 values
variable definition 4: 20 values
variable definition 5: 3 values
then it would result in 5 x 2 x 10 x 20 x 3 = 6000 signals.
Testing your query definition
Test Mode
The query definition contains a field called "TestMode" which is false by default. When test mode is enabled, the signals and conditions are not accessible by Seeq. Instead, the query for each signal/condition is printed to the log file log/jvm-link/sql-v2-test.log which can be found in the Seeq data folder.
Test mode is useful for checking the query definition before bringing the signals and conditions into Seeq. For example, if you expect 100 signals but sql-v2-test.log shows 10,000 signals, you'll want to debug your query definition before bringing those signals or conditions into Seeq.
The log entries for the previous example would look like:
sql-v2-test.log
2018-05-14T13:40:23.179-07:00[America/Los_Angeles]
Query Definition: MyFomUseCase
SELECT fom_time, fom_value FROM fom WHERE run = ${myRun} AND fom_type='${myType}'
expands to 11 signal(s):
SIGNAL NAME QUERY
Run 1 volume SELECT fom_time, fom_value FROM fom WHERE run = 1 AND fom_type='volume'
Run 5 volume SELECT fom_time, fom_value FROM fom WHERE run = 5 AND fom_type='volume'
Run 2 temperature SELECT fom_time, fom_value FROM fom WHERE run = 2 AND fom_type='temperature'
Run 2 volume SELECT fom_time, fom_value FROM fom WHERE run = 2 AND fom_type='volume'
Run 2 thickness SELECT fom_time, fom_value FROM fom WHERE run = 2 AND fom_type='thickness'
Run 1 thickness SELECT fom_time, fom_value FROM fom WHERE run = 1 AND fom_type='thickness'
Run 4 temperature SELECT fom_time, fom_value FROM fom WHERE run = 4 AND fom_type='temperature'
Run 1 temperature SELECT fom_time, fom_value FROM fom WHERE run = 1 AND fom_type='temperature'
Run 5 thickness SELECT fom_time, fom_value FROM fom WHERE run = 5 AND fom_type='thickness'
Run 3 thickness SELECT fom_time, fom_value FROM fom WHERE run = 3 AND fom_type='thickness'
Run 4 thickness SELECT fom_time, fom_value FROM fom WHERE run = 4 AND fom_type='thickness'
Testing the sample / capsule retrieval queries during indexing
When a connection is established with the SQL database, all the signals, conditions, and scalars found are indexed by Seeq. In addition, the queries used to retrieve signal samples and condition capsules are tested for correctness. If a problem is found, it is logged as a warning in the log file. You can search the log file for these warnings and proactively correct the problems. This will prevent an error later when someone tries to trend the signal or condition. The warnings look something like this.
Example warning
WARN 2019-04-23T12:39:04.164-07:00 [Metadata sync for JVM Agent: SQL: Postgres V2 UTC: 3ec583d2-3dbf-4e57-bc24-b4a2e8d214bb] com.seeq.link.connectors.sql2.SqlConnectionV2 - SIGNAL 'Lab volume' from Query Definition 'LabSignals' with query 'SELECT run_start, volume FROM MyFakeTable' will fail to retrieve samples. Please correct the Query Definition. Error: java.sql.SQLException: Error executing query 'SELECT WorkStart, volume FROM MyFakeTable LIMIT 0'. ERROR: relation "myfaketable" does not exist
WARN 2019-04-23T12:57:26.787-07:00 [Metadata sync for JVM Agent: SQL: Postgres V2 UTC: 3ec583d2-3dbf-4e57-bc24-b4a2e8d214bb] com.seeq.link.connectors.sql2.SqlConnectionV2 - CONDITION 'Runs' from Query Definition 'MyRunsCondition' with query 'SELECT run_start, run_end FROM MyFakeTable' will fail to retrieve capsules. Please correct the Query Definition. Error: java.sql.SQLException: Error executing query 'SELECT workstart, workend FROM MyFakeTable LIMIT 0'. ERROR: relation "myfaketable" does not exist
To disable this testing, set the query definition field "TestQueriesDuringSync" to false. True is the default.
More Inspiration
Because SQL is so flexible, your query definitions can get quite creative. Here are some ideas for inspiration.
Shifting the signal key or condition start in time (Example 12)
Perhaps it is desired that the signal key or condition start be shifted forward in time by 6 hours.
The signal in Example 8 used this query:
SELECT run_start, ${myMeasurement} FROM LabSignals
To shift that signal forward in time by 6 hours, just adjust the query like so.
MySql |
|
MS SQL Server |
|
Postgres/Redshift |
|
Oracle | submit your solution |
See the rule "First column must have a name" for more details on the extra SELECT * FROM (). This rule applies to signals and conditions.
Using SQL IF to Determine Linear vs Step Interpolation (Example 13)
Using the FOM example from above, I can specify step interpolation for Run 1 and linear interpolation for all the other runs by using an SQL IF statement. This example is in MS SQL Server format.
SQL IF Statement (MS SQL Server)
if ${run}=1
begin
select 'step'
end
else
begin
select 'linear'
end
JSON doesn't allow line breaks in the SQL statements so the query definition looks like:
Query definition with SQL IF statement
"QueryDefinitions" : [ {
"Name" : "MyFomUseCase",
"Type" : "SIGNAL",
"Sql" : "SELECT fom_time, fom_value FROM fom WHERE run = ${myRun} AND fom_type='${myType}'",
"Enabled" : true,
"TestMode" : false,
"Variables" : [ {
"Names" : [ "myRun", "myType" ],
"Values" : [ [ "${result}" ] ],
"Sql" : "select distinct run, fom_type from fom"
} ],
"Properties" : [ {
"Name" : "Name",
"Value" : "Run ${myRun} ${myType}",
"Sql" : null,
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "${result}",
"Sql" : "if ${myRun}=1 begin select 'step' end else begin select 'linear' end,
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "24d",
"Sql" : null,
"Uom" : "string"
} ]
} ]In this example, IF was used to determine the Interpolation Method but this concept could be applied to any item or capsule property.
Using SQL SUBSTRING to Extract UOM from Column Name (Example 14)
Perhaps my LabSignals table from earlier looked like this instead where the unit of measure was embedded in the column name.
LabSignals table with UOM in column name (MS SQL Server format)
CREATE TABLE LabSignals
(
run_start datetime null,
run_end datetime null,
volume_litre decimal(3,1) null,
temperature_degf real null,
thickness_mil int null,
cost_$ decimal(6,2) null
)
INSERT INTO dbo.LabSignals (run_start, run_end, volume_litre, temperature_degf, thickness_mil, cost_$ ) VALUES
('2016-08-16 10:00:00','2016-08-16 12:15:00', 2.1, 51.2, 18, 3793.87)The signals can be given those units by using SQL SUBSTRING (MS SQL Server). The query definition from Example 8 then becomes:
Query definition using SUBSTRING
"QueryDefinitions" : [ {
"Name" : "MyMeasurementSignals",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, ${myMeasurement} FROM LabSignals",
"Enabled" : true,
"TestMode" : false,
"Variables" : [ {
"Names" : [ "myMeasurement" ],
"Values" : [ [ "${result}" ] ],
"Sql" : "select column_name from information_schema.columns where table_name='labsignals' and column_name!='run_start' and column_name!='run_end'"
} ],
"Properties" : [ {
"Name" : "Name",
"Value" : "Measurement of ${myMeasurement}",
"Uom" : "string"
}, {
"Name" : "Interpolation Method",
"Value" : "linear",
"Uom" : "string"
}, {
"Name" : "Maximum Interpolation",
"Value" : "2d",
"Uom" : "string"
}, {
"Name" : "Value Unit Of Measure",
"Value" : "${result}",
"Sql" : "SELECT SUBSTRING('${column}', CHARINDEX('_','${column}')+1, LEN('${column}'))",
"Uom" : "string"
} ]
} ]In this example, SUBSTRING was used to extract UOMs but the concept could be applied to a number of use cases.
Converting (casting) data types in the SQL query
Sometimes data in SQL may not be the right type required to display. One example is if a date or timestamp is stored as a string instead of a date. Numbers can also be stored as strings and need to be converted to display numeric signals. Each of these conversions will be slightly specific to the SQL database, but here are some examples to get started. See the rule "First column must have a name" for more details on the extra SELECT * FROM ().
MS SQL Server |
CODE
|
MySQL | submit your solution |
Postgres/Redshift | submit your solution |
Oracle | submit your solution |
Ambiguous column names when using JOIN or schemas
If the query is a JOIN on two tables and each table has a column of the same name, the column name may be ambiguous.
Original query: SELECT table1.StartTime, table2.EndTime FROM table1 INNER JOIN table2 ON table1.key=table2.key
In this example, both tables have a column named StartTime. Seeq adds a WHERE clause for StartTime but doesn't know which table to reference. This can be solved by adding a SELECT * FROM around the query as discussed in the section "The first column must have a name".
Modified query: SELECT * FROM (SELECT table1.StartTime, table2.EndTime FROM table1 INNER JOIN table2 ON table1.key=table2.key) AS foo
The same situation could be encountered when using schemas.
Original query: SELECT s1t1.StartTime, s2t1.EndTime FROM schema1.table1 s1t1 INNER JOIN schema2.table1 s2t1 on s1t1.key=s2t1.key
Modified query: SELECT * FROM (SELECT s1t1.StartTime, s2t1.EndTime FROM schema1.table1 s1t1 INNER JOIN schema2.table1 s2t1 on s1t1.key=s2t1.key) AS foo
Oracle Tip Regarding Case Sensitivity
Working with Oracle can be a little trickier than the other databases due to Oracle's handling of case. Example 9 had to be massaged for Oracle.
The Oracle LabSignals table was created with the same table name and column names as the above Postgres example. So the table name was mixed case and the column names were lower case.
CREATE TABLE LabSignals
(
id nchar(20) not null,
workstart date null,
workend date null,
volume number null,
temperature number null,
thickness int null,
cost number null
);But when asking Oracle for the column names of the table, this didn't work:
SELECT column_name FROM all_tab_columns WHERE table_name='LabSignals' AND column_name!='run_start' AND column_name!='run_end'
Oracle can't find the table or columns unless all caps are used:
SELECT column_name FROM all_tab_columns WHERE table_name='LABSIGNALS' AND column_name!='RUN_START' AND column_name!='RUN_END'
Oracle also returned all the column names in all caps so:
${myMeasurement} = VOLUME, THICKNESS, TEMPERATURE, COST
which meant that this query didn't return any results because the table LabSignalMetadata only has a row with the value "volume" and not "VOLUME".
SELECT units FROM LabSignalMetadata WHERE measurement='${myMeasurement}'
This was fixed by using lower in this query:
SELECT lower(column_name) FROM all_tab_columns WHERE table_name='LABSIGNALS' AND column_name!='RUN_START' AND column_name!='RUN_END'
Columns Named with Spaces, Reserved Words, Numbers, Case Sensitivity
SQL best practices do not recommend creating columns with the following types of names:
Names containing spaces
Names starting with a digit (0-9) such as 9 or 4foo. In most databases, a query such as
SELECT 4foo FROM mytablewill return a column named 4foo where every row contains the value 4.Names that are reserved words
To see the list of reserved words for a specific database, search the internet. For example, search for "Oracle reserved words".
Depending on the SQL database, columns with case sensitive column names can also be tricky.
If you have column names with these problems, you can work around them using quotes.
Columns Names with Spaces, Reserved Words, and Numbers in Databricks
During table creation, Databricks automatically inserts underscores to correct the column names that have spaces, numbers, or reserved words in them. Because of this, query definitions built using the table badpractice will return column names that are already underscore-corrected by Databricks. This will not match the column names expected by Bad Practice system tests and will cause the tests to fail. A workaround is to read the underscored column names from the database but create the signals using column names with spaces.
An example query definition using this method is shown below:
{
"Name": "BadPractices",
"Type": "SIGNAL",
"Sql": "SELECT ${_myKey}, ${_myValue} FROM default.badpractice",
"Enabled": true,
"TestMode": false,
"Variables": [
{
"Names": [
"_myKey",
"_myValue",
"myKey",
"myValue" ],
"Values": [
[
"_HisTimestamp",
"_my_ID",
"HisTimestamp",
"my ID" ],
[
"_HisTimestamp",
"ID",
"HisTimestamp",
"ID" ],
],
"Sql": null }
],
"Properties": [
{
"Name": "Name",
"Value": "AT Bad Practice ${myKey} ${myValue}",
"Sql": null,
"Uom": "string" },
{
"Name": "Interpolation Method",
"Value": "linear",
"Sql": null,
"Uom": "string" },
{
"Name": "Maximum Interpolation",
"Value": "2d",
"Sql": null,
"Uom": "string" }
],
"CapsuleProperties": null
}Columns Names with Spaces, Reserved Words, and Numbers in Denodo
During table creation, Denodo automatically replacement names to correct the column names that have spaces, numbers, or reserved words in them. Because of this, query definitions built using the table badpractice will return column names that may not resemble the original column names. You can change the autogenerated column names to something more familiar by running a command similar to ALTER TABLE badpractice (ALTER COLUMN myid_0 RENAME _my_ID); . This probably will not match the column names expected by Bad Practice system tests and will cause the tests to fail. A workaround is to read the column names from the database but create the signals using column names with spaces similar to the example shown for Databricks.
Quotes
To select one of these types of columns, quotes are needed. Most databases use double quotes (") but MySql uses the backtick single quote (`).
Double quotes need to be escaped (backslashed) when used in a json query definition file since the double quote already has meaning in json.
Original queries | Quoted queries (most databases), escaping required | Quoted queries (MySql) |
|---|---|---|
|
|
|
|
|
|
|
|
|
Looking back at Example 8, if you expected the ${myMeasurement} results to be column names with numeric names, the query definition would be modified like so:
"QueryDefinitions" : [ {
"Name" : "MyMeasurementSignals",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, \"${myMeasurement}\" FROM LabSignals",
...Or if MySql, like so:
"QueryDefinitions" : [ {
"Name" : "MyMeasurementSignals",
"Type" : "SIGNAL",
"Sql" : "SELECT run_start, `${myMeasurement}` FROM LabSignals",
...CONDITION Query Definition types with a calculated End Time Column
When the End Time is a calculated time column you must create the query as a sub-query. This allows the connector to place where filters on the SELECT statement to accurately pull the required amount of data. For example, the following query will create a calculated column called end_time that will be 1 minute greater than start time:
SELECT [start_time],
DATEADD(mi, 1, start_time) AS end_time
,[quality]
,[temperature]
,[comment]
,[id]
FROM [TestDB].[dbo].[CalcTime]This will result in an expected result set:
start_time | end_time | quality | temperature | comment | id |
|---|---|---|---|---|---|
2022-07-31 19:59:39.000 | 2022-07-31 20:00:39.000 | 39 | 261 | BAD | A1234 |
2022-07-31 21:45:01.000 | 2022-07-31 21:46:01.000 | 90 | 212 | OK | A1234 |
2022-07-31 22:52:35.000 | 2022-07-31 22:53:35.000 | 40 | 223 | BAD | A1234 |
However, if a filter is placed on end_time the query will fail
SELECT [start_time],
DATEADD(mi, 1, start_time) AS end_time
,[quality]
,[temperature]
,[comment]
,[id]
FROM [TestDB].[dbo].[CalcTime]
WHERE end_time is NOT NULLwith
Invalid column name 'end_time'.This will cause queries for data to fail in Seeq as we need to identify all rows where start and end times are not null to ensure we pull valid capsules.
To overcome this issue, a subquery can be created:
SELECT
[start_time],
[end_time],
[quality],
[temperature],
[comment],
[id]
FROM
(
SELECT
[start_time],
DATEADD(mi, 1, start_time) AS end_time,
[quality],
[temperature],
[comment],
[id]
FROM
[TestDB].[dbo].[CalcTime]
) AS calc_time
WHERE
end_time is NOT NULLThe WHERE filter criteria is taken into account for the table scan if filters for ID are present, for example. This allows Seeq to safely apply filtering criteria to the query without breaking it.