Using Materialized Views to Increase Indexing Performance
Overview
If you a leveraging a single large denormalized table that contains both metadata and data, especially if there is a large number of group by columns, the indexing performance of the connector might be slow or unable to complete without a timeout. To overcome this, a materialized view can be used within ADX to precompute the Asset Tree information. Note: this is not generally an ideal model, see Example: Accessing Asset Tree Data from an Entity-Timestamp-Value Model for performance and maintenance implications of this model.
Example ADX Data
Example table:
TS | siteId | machineId | lineId | tag | Value |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineA | Temperature | -47.4309 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineA | Pressure | 25.50104 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineA | Power | -14.0308 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineB | Temperature | 79.60899 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineB | Pressure | -27.629 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineB | Power | 99.64653 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineC | Temperature | 32.08159 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineC | Pressure | 79.92259 |
2022-11-03T21:27:47 | Site 1 | Line 1 | MachineC | Power | 162.3627 |
2022-11-03T21:27:47 | Site 1 |
| MachineA | Temperature | 146.625 |
For this example we will load this data into ADX. Executing the query:
ETVData
| take 10
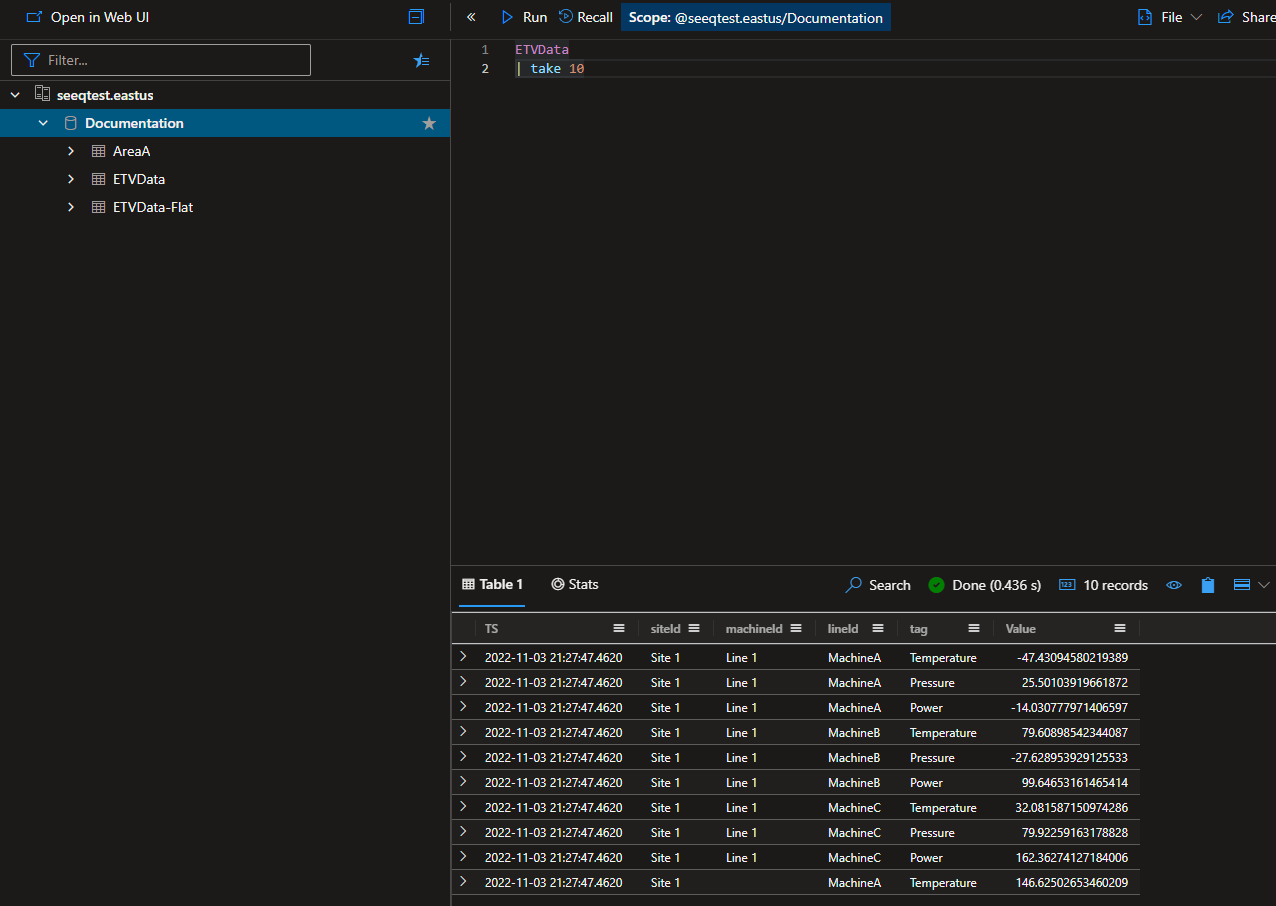
Will result in a table that looks like the image to the right. In this example there are not a lot of rows (only ~52k rows). However, in a realistic system this table could reach into the multi-billion rows. In this case a distinct query including the siteId, lineId, machineId, and tag columns (which is what would be executed during indexing when the GroupBy parameter in the configuration is set to ["siteId","lineId","machineId","tag"]) would generally time out, or in the best case lead to very long indexing times.
Creating a Materialized View
A possible solution to the slow performance issue is to create a materialized view in ADX.
Creating the materialized view would involve a query that looks like this:
.create materialized-view with (backfill=true) AssetView on table ETVData
{
['ETVData']
| distinct siteId, lineId, machineId, tag
| summarize any(*) by siteId, lineId, machineId, tag
}This is going to pre compute all the unique combinations of siteId, lineId, machineId, and tag columns from the ETVData table and store it as a materialized view called AssetView.
In this example we are backfilling so that we instruct ADX to populate the view from the existing data in the table. If we did not include that parameter, the materialized view would only include pre-computed assets from data that was ingested after we created the view. More information, including some considerations can be found here: https://learn.microsoft.com/en-us/azure/data-explorer/kusto/management/materialized-views/materialized-view-create#backfill-a-materialized-view.
Accessing the Materialized View During Indexing
There are two methods to access the data in the materialized view. Depending on the version of the Kusto Engine you are using will determine which one will have to be used. Seeq suggests that customers leverage the V3 engine for greater performance and additional capabilities in ADX.
Using the MetadataQuery to Access Materialized View Metadata
Note: This functionality requires the Kusto Engine V3
This is the recommended approach to accessing the pre-computed asset tree metadata within ADX. This option offers the most flexibility when configuring how to connect Seeq to the metadata.
This method will be very similar to the guide here: Example: Accessing Asset Tree Data from an Entity-Timestamp-Value Model . However, we will me utilizing the MetadataQuery parameter to point the indexing to the materialized view, instead of the denormalized table.
Entity Identity Management
In the example table provided above, the uniqueness is defined via a composite key. This is not ideal in many cases, having a table-unique key per tag is idea. However, in the event this cannot be adjusted within the model, this section will explain how to leverage a composite key to define uniqueness while leveraging a materialized view. To create the uniqueness we will assume that we have to concatenate the sideId, lineId, machineId, and tag column values. To define this across the materialized view and the physical table, we will have to include a composite key in both. For the materialized view, it is the addition of a calculated column as shown below:
.create materialized-view with (backfill=true) AssetView on table ETVData
{
['ETVData']
| distinct siteId, lineId, machineId, tag
| extend tagId = strcat(siteId, lineId, machineId, tag)
| summarize any(*) by siteId, lineId, machineId, tag, tagId
}This query will create a materialized view with a new tagId column to define the uniqueness. Now that we have a singular column on the materialized view side, we will need an equivalent column on the physical table side. For this we will use a stored function. This stored function acts as a view that allows for the tagId column to be included in the result set. This can be achieved with the function creation script below:
.create-or-alter function with (folder = "Seeq") DataTable() {
['ETVData']
| extend tagId = strcat(siteId, lineId, machineId, tag)
| project TS, Value, tagId
}
This function creates the tagId column in the result set allowing for filtering when querying. With the materialized view and the stored functions created, we can now create our connector configuration.
{
"RootAssetName": "Region A",
"GenerateTableAsset": false,
"SignalTables": [
{
"Id": "ETV Data 1",
"Name": "DataTable",
"NameQuery": null,
"GroupBy": [
"siteId",
"lineId",
"machineId",
"tag"
],
"GroupByLimit": 0,
"DataColumns": [
"Value"
],
"DataColumnQuery": null,
"TimeColumn": "TS",
"LastGroupAsSignalName": true,
"TransformQuery": null,
"TimeUnit": null,
"ComputedGroupByResult": null,
"GroupByRequestProperties": null,
"DataRequestProperties": null,
"MetadataQuery": {
"TableName": "AssetView",
"Filters": null,
"Columns": [
"siteId",
"lineId",
"machineId",
"tag",
"tagId"
],
"UniqueKeyColumnName": "tagId"
},
"SignalPropertiesMap": {
"UniqueKey": "tagId"
}
}
],
"ConditionTables": [],
"ApplicationId": "<example application Id>",
"AccessKey": "<example access Key>",
"TenantId": "<example tenant ID>",
"UserName": null,
"UserPassword": null,
"Cluster": "https://<cluster name>.<cluster region>.kusto.windows.net",
"Database": "Documentation"
}In the configuration above you can see we have the GroupBy defined as ["siteId","lineId","machineId","tag"] and we are defining the Name property as DataTable which is the name of the stored function we created above. This is where the data is stored. The MetadataQuery is targeting the materialized view, in this example AssetView. We access each column that will be required by the GroupBy as well as the UniqueKeyColumnName. The UniqueKeyColumnName is leveraging the calculated key we created to define the uniqueness between the materialized view and the stored function.
The SignalPropertiesMap property is required when using the MetadataQuery parameter
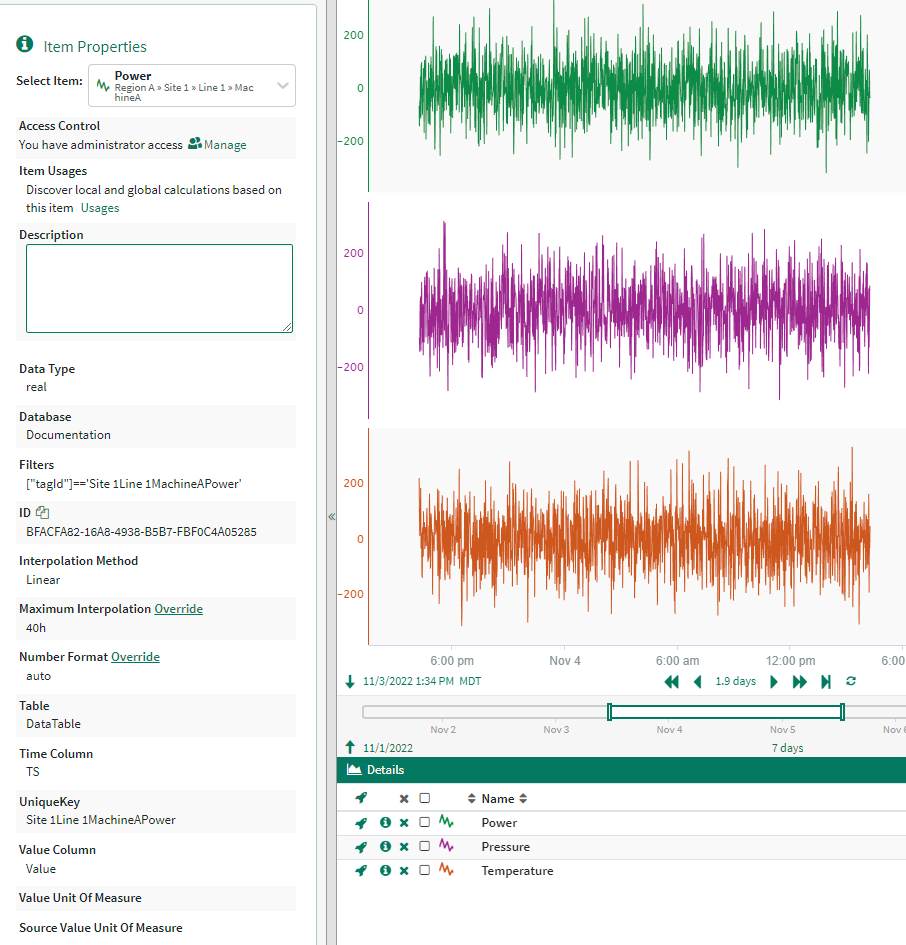
When we access the signals within workbench you can see that the UniqueKey is a property of the signal. This was set by the SignalPropertiesMap in the connector configuration above.
Using the ComputedGroupByResult to Access Materialized View Metadata
This functionality can be leveraged on clusters using the Kusto Engine V2
The ComputedGroupByResult can be leveraged to access the data in the materialized view. This parameter is a Kusto query that accesses a distinct asset group. This Kusto Query must return a result set that includes all of the columns specified within the GroupBy parameter. In this example, our GroupBy parameter is set to ["siteId","lineId","machineId","tag"]. This means that our result from our AssetView materialized view created above must include all four columns. If there are additional columns in your materialized view you could leverage a ComputedGroupByResult like the following:
AssetView | project siteId,lineId,machineId,tagAlternatively, you could leverage the project-away operator (https://learn.microsoft.com/en-us/azure/data-explorer/kusto/query/projectawayoperator ) to remove specific columns.
For this example,
{
"RootAssetName": "Region B",
"GenerateTableAsset": false,
"Tables": [
{
"Id": "ETV Data 2",
"Name": "ETVData",
"NameQuery": null,
"GroupBy": [
"siteId",
"lineId",
"machineId",
"tag"
],
"GroupByLimit": 0,
"DataColumns": [
"Value"
],
"DataColumnQuery": null,
"TimeColumn": "TS",
"LastGroupAsSignalName": true,
"TransformQuery": null,
"TimeUnit": null,
"ComputedGroupByResult": "AssetView",
"GroupByRequestProperties": null,
"DataRequestProperties": null,
"MetadataQuery": {
"TableName": null,
"Filters": null,
"Columns": null,
"UniqueKeyColumnName": null
},
"SignalPropertiesMap": null
}
],
"ApplicationId": "<example application Id>",
"AccessKey": "<example access Key>",
"TenantId": "<example tenant ID>",
"UserName": null,
"UserPassword": null,
"Cluster": "https://<cluster name>.<cluster region>.kusto.windows.net",
"Database": "Documentation"
}This results in an asset tree as below:
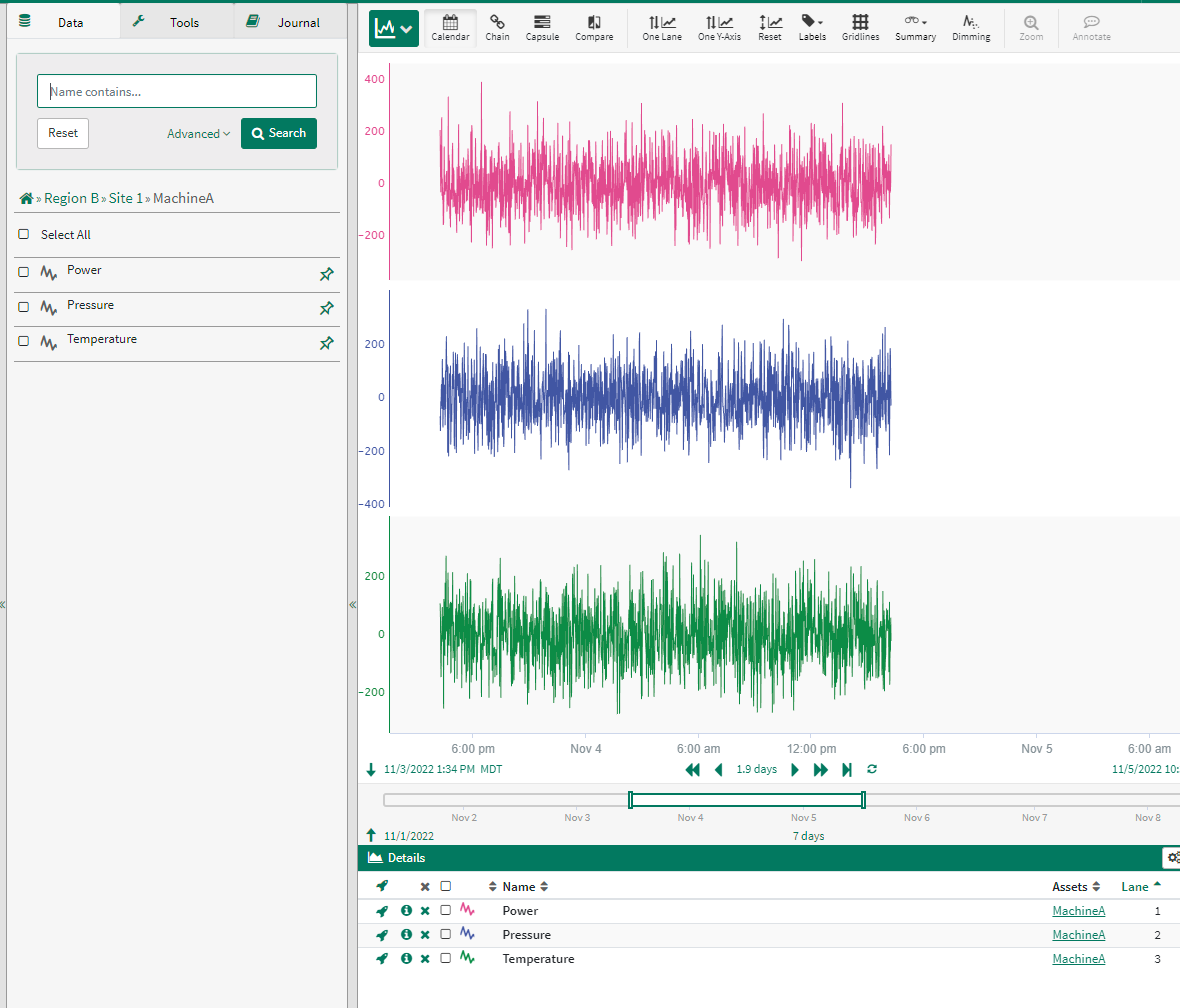
There is no ability to add signal properties such as unit of measure, description, or interpolation method as there is in the MetadataQuery case. However, if you just have a simple distinct asset tree as metadata, this is a usable option.
Retrieving greater than 500,000 Assets
By default, ADX has a limit of 500,000 rows that it can return. when performing the distinct query for all of the columns listed in the GroupBy, there is a chance that a use case could exceed 500,000 rows. If that is the case the GroupByRequestProperties parameter will have to be set with a value of {"notruncation" : "true"}. This will allow ADX to return more than the default 500,000 rows per query.
Note: This is not a requirement when using the MetadataQuery parameter, as that function will automatically page the result.