Understanding Data Caching
Seeq is configured to cache historian data on its local disk to improve data retrieval performance for historical data.
Overview
One of our core principles at Seeq is that data should not be duplicated. We feel strongly about this because the minute that data is duplicated, it is out of date and a host of issues and questions arise as to the integrity and legitimacy of the copy. At the same time, we strive to optimize the user experience of interacting with data in historians. Therefore, to enhance data access performance, Seeq uses a local cache on the Seeq Server's disk. It is a true cache, since its data may be discarded at any time without affecting the integrity of the analytics created in Seeq.
How It Works
Reading/Writing
Data is written to the cache as it is accessed or computed. Data is read from the cache whenever cached data exists in the request time range. For instance, if the user requests data from a series for January, and then requests data for March, the cache will look like this:
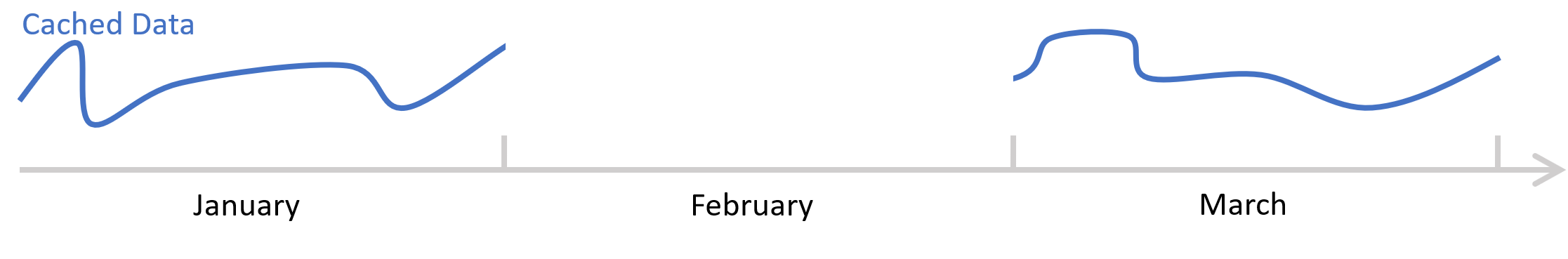
If the user then requests data from Jan 15th through March 15th, the cached data in January and March will be used and the missing February data will be computed or fetched and then written to the cache. The cache will then look like this:

Any subsequent requests for data that overlap January through March will source the overlapping data from the cache, piecing cached data together with new data as necessary. Any requests for data that fall entirely within previously cached regions will use just the cache.
Invalidation
Most of the time series data changes by adding new data, with very infrequent changes to past data. The cache is designed with this property in mind, and only requires invalidation (purging of cached data) when past data is altered. While invalidation of data directly from a datasource is very rare, invalidation of calculated data is reasonably frequent as changes to a calculation itself often requires invalidation of the entire signal and all signals that depend on the affected signal. This invalidation is handled by the system automatically and transparently.
Invalidating cache for an item will also invalidate caches of all calculations based on that item to ensure any data changes are propagated. Performance may be degraded while caches are rebuilt.
Needing to invalidate cache frequently is an anti-pattern that may be addressed with Connector Property Transforms. See https://support.seeq.com/kb/latest/cloud/optimizing-a-datasource-connection for strategies that address frequent data changes.
Invalidating Cache For an Individual Item
When data must be manually invalidated, users can clear (invalidate) the cached data in the advanced options of an item's properties.
Note an item's cache and the cache of calculations based on it can also be cleared by modifying any of the following properties: Interpolation Method, Uncertainty Override, Request Interval Clamp, Historical Data Version, Key Unit Of Measure, Value Unit Of Measure, Source Maximum Interpolation, Override Maximum Interpolation, Unit Of Measure or Maximum Duration.
Invalidating Cache for a Subset of Items in a Datasource
If multiple signals were backfilled, you can use a Connector Property Transform to update the Historical Data Version property for the signals or conditions of interest. See Connector Property Transforms | Invalidating-Cache-For-Matching-Data-IDs for an example. Note that clearing caches for large numbers of items may cause temporary performance problems until caches are rebuilt.
Invalidating Cache For a Datasource
Invalidating cache for an entire datasource may be necessary if the majority of signals or conditions in the datasource undergo historical data changes, or backfilling.
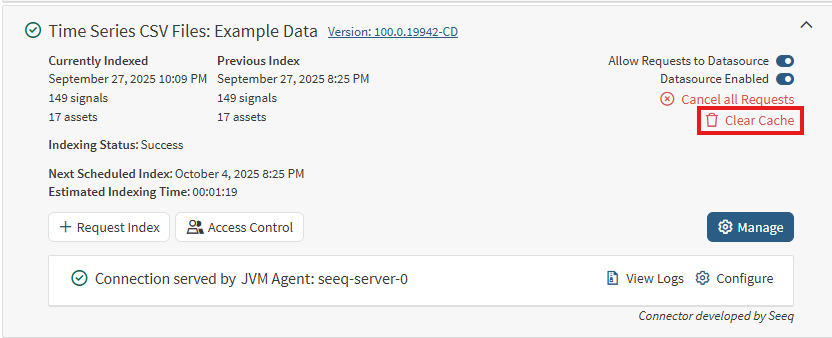
Clearing cache is necessary for correcting data in Seeq if historical data has changed. However, note that clearing cache for the entire datasource may result in poor datasource performance temporarily, until caches are rebuilt. Clearing an entire datasource cache will also clear caches for all calculations that use the datasource data as input.
To clear cache for a particular datasource, navigate to the Datasources tab of the Administration page. Find the applicable datasource and click the Clear Cache button that is outlined in red in the following screenshot: